pbberlin.github.io
Projects up to 2019
Python for researchers (2018, 2020)

-
ZEW press release
-
Get the PDF script
-
For graduate students and postdocs
-
Assuming no experience with programming
-
Three days - four hours each
-
6 hours concepts
-
Repeated in 2020
ExcelDB - tax parameter database (2016-)
- Excel in the web browser: sheets with cells; numbers, formulas, computations, cell comments
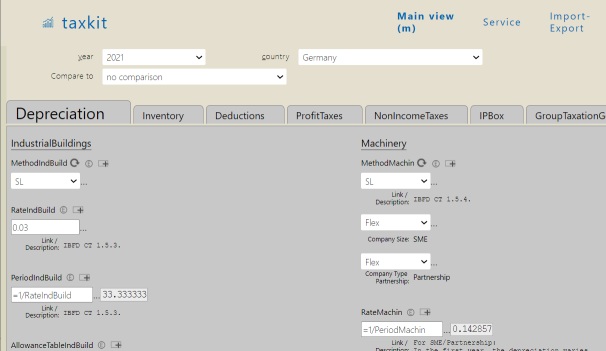
- Additional features
- Sheets can be organized in trees
Diffview for sheets- Versioning of sheets over years, countries etc.
- Sheets have a user definable structure for specific types of data
- LDAP login
- Change log
- Import from Excel - export to Excel
- SQL queries - highly normalized DB schema
- Formulas are compatible to Excel; special functions for taxation (NPV of deduction schemes…)
- Used at ZEW institute…
- For taxation parameters of 20+ countries and 40+ special tax jurisdictions
- Over 25 years into the past
- Parameters for income tax, profit tax, substance- and local tax
-
Written in Golang with under 14.000 LOC
- Closed source
Crawling against Cloudflare
-
Strictly for scientific purposes
-
Over 20 AWS VMs for more than 6 months
-
Selenium being detected and blocked
-
Using tampermonkey and autohotkey Windows scripting
-
Using Python to start/stop OVPN service;
changing VPN host IPs every five requests -
Lowering request frequency to four per minute;
to avoid the stochastic defence algo of Cloudflare -
Auto-solving captchas, using an undisclosed technique
(no “clickworkers” involved)
Bitcoin micropayments for small websites (2015)
-
An app engine website serving HTTP content from Google cloud datastore
-
Using Google identity toolkit (gitkit) version 1 for social media logins
-
Using the bitcoin transaction API of coinbase.com to purchase premium content; saving article purchases in the cloud datastore
-
By 2018, all components of the website had become obsolete. Gitkit no longer exists. App engine architecture for Golang has changed.
-
Result 1: Bitcoin transactions took up to 2 hours
-
Result 2: Bitcoin transactions had to be tipped in order to get executed
-
Result 3: Bitcoin transactions are not suited for micropayments under one Dollar
-
Result 4: Bitcoin and other blockchain based systems are subject to the CAP theorem
Graphite monitoring service (2015)
-
Right before Prometheus came into existence, I was tasked to setup a central monitoring service at Idealo Internet Ltd. The company decided on Graphite.
-
Lots of advance testing and preparation
-
Rolling out the Nagios configs to 1000+ machines using puppet
-
Collecting monitoring data from 1000+ Linux servers
-
Common Linux parameters and specific measures for MySQL servers, Java webservers etc.
-
Batches of measures every five minutes, partly every minute
-
Compacting time series databases after four weeks and further after one year is essential to maintain performance
-
The Python scripts in the Graphite Ceres storage engine doing the compacting needed some actual implementation; but I am sure, everything is perfect by now
-
Setting up ten Python data collector processes doing the persisting of up to 100.000 measures per second (benchmarked)
-
Still only one initial listener socket, distributing the incoming data
-
Result 1: Really nice graphite-web charts - and SMS alarms
-
Result 2: The mysterious
mysqldcrashes every nine months remained mysterious -
Result 3: Python on the server is cumbersome
MySQL master-master cluster (2015)
-
Another go at improving the huge master-slave database systems at Idealo Internet Ltd
-
Trying a master-master clustering system:
Percona Galera XtraDB cluster -
Using HaProxy as load balancer
-
Setup and config guide - partly in German
-
Result 1: Automatic failover traded in for reduced write performance
-
Result 2:
rejoininga broken node is cumbersome
mongo-stress (2014)
-
Large cloud setup to investigate the scaling of MongoDB clusters under various types of loads for Idealo Internet Ltd
-
Three shards - three MongoDB servers
-
Four MongoDB client machines, performing inserts, updates and deletes
-
All operations summarized in highcharts webbrowser view
-
First use of Golang for synchronizing lots of parallel data streams via
channelsandfor…select… loops -
Insertion performance using monotonically increasing IDs versus GUIDs
-
Result 1: MongoDB scales linearly for GUID based insertions, because they are equally distributed across shards (nodes). Monotonically increasing IDs dont scale.
-
Result 2: No re-balancing of sparse/emptied
chunksbetween nodes, possibly not implemented then => skewed load when monotonically increasing IDs are deleted after a while -
Result 3: Fitting the
hot setinto memory for each node dominates perfomance; and so are the Linux hard disk flushing settings -
Result 4: Good luck with restoring your cluster once its broken
-
Result 5: GUIDs are partly based on the client’s MAC address; watch out for skewered loads…
Apartment sharing sites (2010-2012)
-
Dynamic ranking of apartment result list, based on recent revenue and Google analytics
-
SEO despair